Billions of end users Pre LLMs: "How to convert my document to PDF?".
Millions of developers post LLMs: "How to convert a PDF to plain text?"
Billions of end users Pre LLMs: "How to convert my document to PDF?".
Millions of developers post LLMs: "How to convert a PDF to plain text?"
Application Developers in 2015: Oh no, a lot of creative work is taken over by open source software, we mostly write glue code now.
Vibe Coders in 2025: Oh no, AI is not good enough for creative tasks. I have to think now!
Claude: Let me ask follow up questions at the end of each answer to maximize engagement.
Gemini: Let me reference a YouTube video at the end of each answer to maximize ad revenue.
I used an em dash when replying to an AI chatbot. Now the AI is left wondering if I'm a human or not.
Claude wishes me "Good morning", "Good evening" and so on during the day.
Yet Claude never says "Why are you awake at this time?" when you open it in the middle of the night.
I asked Claude a very basic question about the sum rule in differentiation, and it turned into a fun conversation about how deep learning works.
I'm getting suboptimal results when vibe-coding CSS animations. Can talented open-source developers please rise up to the occasion and work for free to help develop better training data for all of us? Cheers!
I did not pay much attention to the AI wave for a while, even after the ChatGPT moment.
But it all changed a few months ago when I vibe coded a couple of web pages on Lovable and the generated UI looked much better than what I could have developed on my own. I got excited about learning how GenAI applications work under the hood and started exploring basic Machine Learning concepts as well.
However, I believe using creators' data without their permission is unethical. At the same time, as a software developer, I don't want to be left behind and not rely on AI tools. I'm sure most knowledge workers are facing this ethical dilemma.
After watching an interview with Karen Hao about her book, The empire of AI, the moral conundrum feels more real.
I'm evaluating pyinfra in order to deploy TechTrack, my Hacker News client app.
pyinfra's documentation is still sparse, so I'm using DeepWiki, yet another AI tool, to get an overview of how the codebase is structured and what each major component does. DeepWiki looks very promising and provides an easy ramp when jumping into new codebases.
Check out both pyinfra and DeepWiki and tell me what you think!
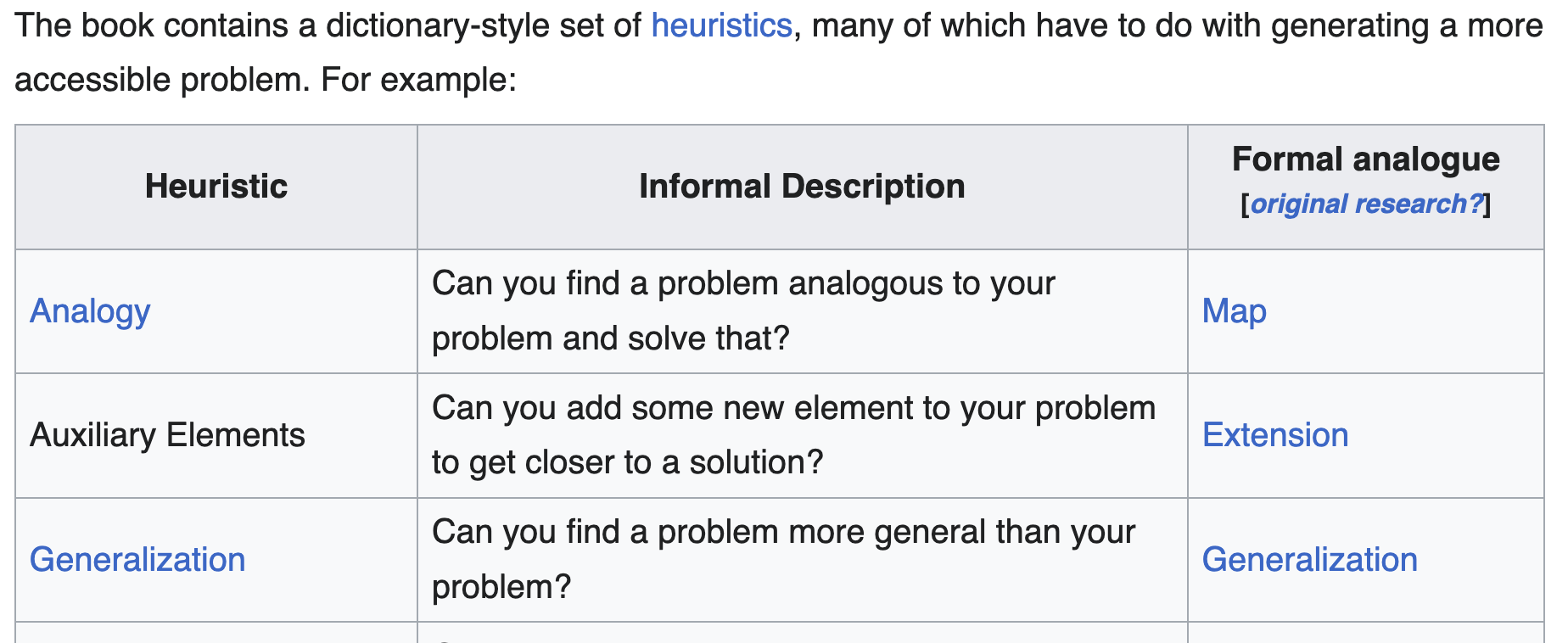
The mathematician George Polya, in his 1945 book, "How to Solve It", described how asking "Can you solve a more general problem?" is a useful problem solving strategy.
Demis Hassabis taking it to heart now: "We'll solve AGI first and then use it to solve everything else."
Everyone's favourite subject is themselves. Even Claude AI seemed more excited than usual when I asked it to help debug my first simple neural network implementation.
